
(c) Erik Hollnagel, 2020
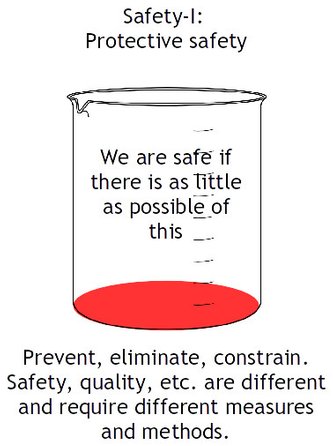
The focus of Safety-I is on events with adverse outcomes - on things that go wrong. These events are usually rare or infrequent.
These events are analysed in order to understand how they happen.
The purpose of this analysis is to make sure that there will be no adverse outcomes the next time the same situation occurs.
But we cannot achieve a state of safety (not even Safety-I) by looking only at accidents and incidents. Such analyses have two serious limitations:
- Explanations are linear (cause-effect analyses, as in an Ishikawa diagram).
- The analysis represents a single instance or snapshot of system failure, but not of system functioning.

The focus of Safety-II is on everything that happens - on things that go right as well as on things that go wrong. Things usually go right most of the time - they are the rule rather than the exception.
In order to achieve a state of safety - whether Safety-I or Safety-II - we need to understand what happens when things go well. We need to understand the nature of everyday performance variability. Indeed, even when we notice that something has gone wrong, we should realise that it probably has been done many times before (and will be done many times again) and that it usually has gone right - and will go right.
Typical performance is continuous rather than discrete, which means that proposals for improvements refer to a broad spectrum of performance rather than to single instances.
Protective safety and productive safety: Safety-I and Safety-II in a nutshell
The analysis represents a single instance or snapshot of system failure, but not of system functioning. Lessons learned from accident analyses are (logically) only valid if exactly the same instance or configuration occurs again.